花和尚是一个定居西雅图的程序员,拥有多年系统设计和开发经验。喜欢研究和总结System Design, 并传授给大家。花和尚在MITBBS一篇 "我的System Design总结" 文章获得超过8万访问量,并被多家网站和博客转载。
Netflix开源项目Deep Dive
上篇给了大家很多Netflix和Netflix OSS的context。本篇将直入主题,在这里笔者选择几个有代表性且用户数量多的明星项目跟大家一起分享。
Asgard/Spinnaker
我还记得new grad的时候进公司不久问了老板一个问题:"我们每次deploy时,service就down了,我们岂不是会丢掉很多requests?" 我当时的老板一口茶差点没喷出来。
后来我才知道原来changes可以分步deploy到hosts上。具体步骤分为3步:
当然,说起来简单,如何实现对ASG分批host的deployment?如何在alarm被trigger后rollback deployment?这些都不是一个trivial的问题。幸运的是,Asgard帮我们解决了这个问题。
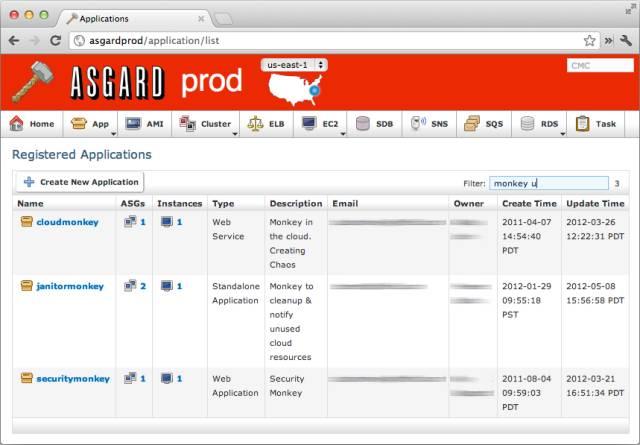
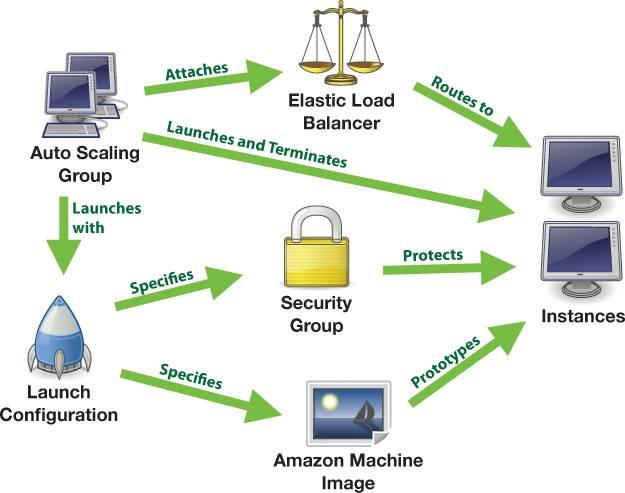
ASG, AMI和ELB在deployment中的交互过程
Asgard解决了deployment的问题,但也带来了新问题:

Spinnaker
值得一提的是,Spinnaker的出现并不是说明Asgard是不重要的,而是在Asgard的原有functionality的基础上又添加了更多功能来实现CD。它解决了笔者抛出的以上3个问题:
Link: http://techblog.netflix.com/2015/11/global-continuous-delivery-with.html
See also: Jenkins, Amazon Apollo/AWS CodeDeploy & CodePipeline
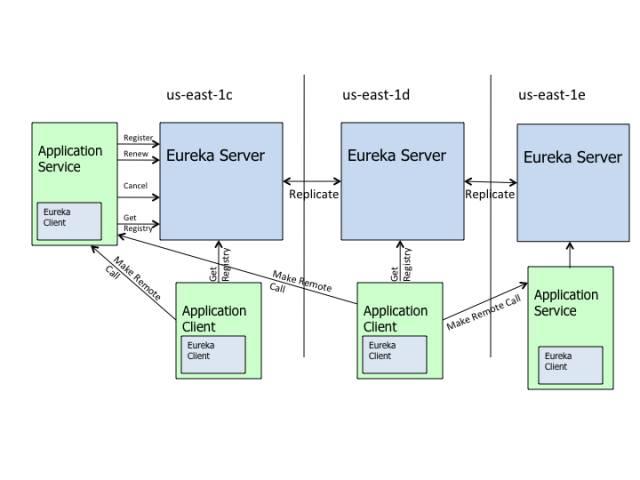
Eureka
Eureka是Netflix提供的mid-tier service registry service。它的主要作用是Service Discovery。笔者管它叫做"Service of Services"。
你可能会问:为什么不能用普通的VIP?
原因是AWS的EC2 instances come and go,并不是static的hosts,所以也没有static的IP和hostname。这就需要更复杂的load balancer来处理不停变化的cluster。
你可能又会问:那AWS自带的ELB总可以handle EC2 instances的come and go的不确定性吧?为什么不直接使用而要reinvent the wheel呢?
这是个好问题。要解释清楚这个事情 还要牵扯到Microservices的概念。
Microservices究竟是什么意思呢?用笔者自己的话来解释,其实就是一种观点:这种观点认为与其做一个超级无敌大的单个web application(a.k.a. Monolithic application)来handle所有business logic,不如做一批量的microservices,每一个microservice处理一块相对独立的business logic,然后把所有microservices以dependency graph的形式相互依存连接起来。
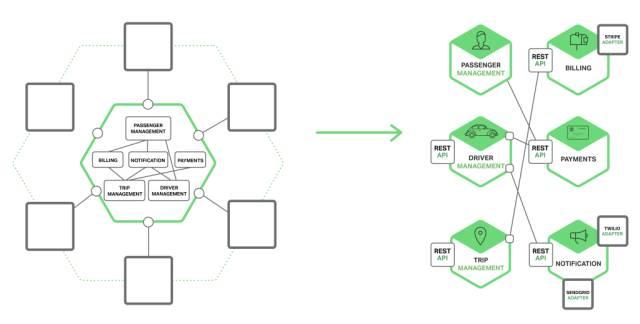
Monolithic application vs. Microservices
Microservices的优点有:
关于更深入的Microservices的知识我会单独开一篇文章讲述。
再回来讲ELB,ELB的确可以担负起load balancing这块的责任。那么这种情况下,每一个microservice的前面都需要加一个ELB来做load balancer。这样做的缺点是:
Ribbon

Ribbon是client-side的load balancing tool。它和Eureka一起实现了internal service ELB的功能。
举一个例子,当一个request要从service A发送给service B(也就是Service A的dependency)的时候,service A会先make a request to Eureka,得到service B的metadata,包括hosts信息。然后Ribbon这个library会被调用读取host信息,做出选择来访问其中的一个host然后得到response。
Ribbon有几种选择模式:
同时,Ribbon还实时监控每个ASG的健康状况。当一个ASG的request数量超过最大值或者当ASG down掉的时候,Ribbon会直接drop掉整个ASG。AWS虽然贵为最稳定的云计算平台,但每隔一两年搞掉一两个ASG甚至一个region还是很正常的,而Netflix网站和traffic却没有因此受到丝毫影响,笔者猜测Ribbon应该是居功至伟。
Link: http://techblog.netflix.com/2013/01/announcing-ribbon-tying-netflix-mid.html
Hystrix

Hystrix的作用是client-side fail tolerance management。还用刚才的例子:假如Service B down掉了,Service A是否也不能运行?在Netflix的设定下,假如Service A是Netflix的主页面,而Service B是Netflix的recommendation service,那么我们完全可以认为即使Service B完全无法运转,Service A也应该继续运行,即使提供的是degraded experience。
比如在这种情况下,Service A应该得到的结果可以是一个pre-defined top picks list,这样recommend给用户的就是最popular的节目,在一定时间内也不会有任何问题(顺带吐槽一下,大多数recommendation system的performance其实比直接给最popular的shows也没好到哪里去。。。)。
Hystrix还提供了dashboard,供你实时观测有多少request得到的response是fallback behavior,从而估测到每个dependency service的健康状况。只能说非常贴心。
Link: http://techblog.netflix.com/2012/11/hystrix.html
Simian Army/Chaos Monkey

测试Microservices的稳定性一直是个世界级难题,Netflix拥有上百个services,无数种挂掉的combination,作为一个程序猿,我怎么知道在每一种scenario下Netflix是否还能正常运行?你需要另一个猴子帮你:Introducing Simian Army and Chaos Monkey。
Simian Army直译就是类人猿军队,是一个测试套装。其中最有名的就是Chaos Monkey,直译就是制造混乱的猴子。
这个猴子用来干什么呢?它在所有service的dependency graph里,每次随机挑几个service,把它们弄挂(当然testing是在test stage进行的,这时候spinnaker就派上用场了),看看Netflix as a whole的输出结果是否还是expected的(expected behavior严重依赖于Hystrix)。
笔者工作中也进行过很多次gameday,一起测试org下的几十个services,但每一次都是固定的测试某些个系统挂掉的scenario。当笔者第一次看presentation听到这个tool的时候可想而知是相当被震撼到的,也深深的成为了Netflix的脑残粉。
Link: http://techblog.netflix.com/2012/07/chaos-monkey-released-into-wild.html
小结
甩了一堆纯干货,想必大家都有点审美疲劳。我们歇一下,这篇就讲到这里。
如果你问本文涵盖了所有Netflix OSS的精华么?答案是否定的。笔者所希望的是,以后当你考虑用一个架构,或者在实践中发现了一个painpoint而且觉得是一个distributed system的通用问题的时候,不妨搜一搜Netflix OSS,说不定早就被Netflix的架构师解决了。
Netflix开源项目Deep Dive
上篇给了大家很多Netflix和Netflix OSS的context。本篇将直入主题,在这里笔者选择几个有代表性且用户数量多的明星项目跟大家一起分享。
Asgard/Spinnaker
我还记得new grad的时候进公司不久问了老板一个问题:"我们每次deploy时,service就down了,我们岂不是会丢掉很多requests?" 我当时的老板一口茶差点没喷出来。
后来我才知道原来changes可以分步deploy到hosts上。具体步骤分为3步:
- 在deployment前从VIP/Load balancer/DNS disable该host;
- Deployment。host运行app版本被更新为最新版;
- 在deployment完成后再把host加回VIP/Load balancer/DNS。
当然,说起来简单,如何实现对ASG分批host的deployment?如何在alarm被trigger后rollback deployment?这些都不是一个trivial的问题。幸运的是,Asgard帮我们解决了这个问题。
ASG, AMI和ELB在deployment中的交互过程
Asgard解决了deployment的问题,但也带来了新问题:
- 随着业界的发展 Continuous Delivery(a.k.a. CD)成了下一个the thing。SDE们希望随时可以test并deploy 且拥有不同的deployment stage(e.g. alpha, beta, gamma, onebox and prod)
- 如果我不想使用AWS怎么办?
- 很多人fork了asgard的branch并没有contribute back
Spinnaker
值得一提的是,Spinnaker的出现并不是说明Asgard是不重要的,而是在Asgard的原有functionality的基础上又添加了更多功能来实现CD。它解决了笔者抛出的以上3个问题:
- 提供了一个完整的Deployment Pipeline。包含了不同的stage和testing workflow。
- 支持多个平台,包括AWS, Google Cloud Platform, Microsoft Azure, etc。
- 更开放的开源平台,支持community support and contribution。
Link: http://techblog.netflix.com/2015/11/global-continuous-delivery-with.html
See also: Jenkins, Amazon Apollo/AWS CodeDeploy & CodePipeline
Eureka
Eureka是Netflix提供的mid-tier service registry service。它的主要作用是Service Discovery。笔者管它叫做"Service of Services"。
你可能会问:为什么不能用普通的VIP?
原因是AWS的EC2 instances come and go,并不是static的hosts,所以也没有static的IP和hostname。这就需要更复杂的load balancer来处理不停变化的cluster。
你可能又会问:那AWS自带的ELB总可以handle EC2 instances的come and go的不确定性吧?为什么不直接使用而要reinvent the wheel呢?
这是个好问题。要解释清楚这个事情 还要牵扯到Microservices的概念。
Microservices究竟是什么意思呢?用笔者自己的话来解释,其实就是一种观点:这种观点认为与其做一个超级无敌大的单个web application(a.k.a. Monolithic application)来handle所有business logic,不如做一批量的microservices,每一个microservice处理一块相对独立的business logic,然后把所有microservices以dependency graph的形式相互依存连接起来。
Monolithic application vs. Microservices
Microservices的优点有:
- 每个component可以独立选择programming language,Framework。
- 每个component可以独立scale
- 每个component可以有独立的strategy实现failover或是degraded experience,而不需要一个大app倒下整个网站都不能用。
关于更深入的Microservices的知识我会单独开一篇文章讲述。
再回来讲ELB,ELB的确可以担负起load balancing这块的责任。那么这种情况下,每一个microservice的前面都需要加一个ELB来做load balancer。这样做的缺点是:
- ELB的主要用途是做edge service的load balancer。属于heavy-lifting的load balancer,cost不小,也有点大材小用。
- ELB使用的是外部IP,如果你的service并没有准备handle external traffic,那么too bad,全世界都知道你有这个service了。
Ribbon
Ribbon是client-side的load balancing tool。它和Eureka一起实现了internal service ELB的功能。
举一个例子,当一个request要从service A发送给service B(也就是Service A的dependency)的时候,service A会先make a request to Eureka,得到service B的metadata,包括hosts信息。然后Ribbon这个library会被调用读取host信息,做出选择来访问其中的一个host然后得到response。
Ribbon有几种选择模式:
- Simple Round Robin LB
- Weighted Response Time LB
- Zone Aware Round Robin LB
- Random LB
同时,Ribbon还实时监控每个ASG的健康状况。当一个ASG的request数量超过最大值或者当ASG down掉的时候,Ribbon会直接drop掉整个ASG。AWS虽然贵为最稳定的云计算平台,但每隔一两年搞掉一两个ASG甚至一个region还是很正常的,而Netflix网站和traffic却没有因此受到丝毫影响,笔者猜测Ribbon应该是居功至伟。
Link: http://techblog.netflix.com/2013/01/announcing-ribbon-tying-netflix-mid.html
Hystrix
Hystrix的作用是client-side fail tolerance management。还用刚才的例子:假如Service B down掉了,Service A是否也不能运行?在Netflix的设定下,假如Service A是Netflix的主页面,而Service B是Netflix的recommendation service,那么我们完全可以认为即使Service B完全无法运转,Service A也应该继续运行,即使提供的是degraded experience。
比如在这种情况下,Service A应该得到的结果可以是一个pre-defined top picks list,这样recommend给用户的就是最popular的节目,在一定时间内也不会有任何问题(顺带吐槽一下,大多数recommendation system的performance其实比直接给最popular的shows也没好到哪里去。。。)。
Hystrix还提供了dashboard,供你实时观测有多少request得到的response是fallback behavior,从而估测到每个dependency service的健康状况。只能说非常贴心。
Link: http://techblog.netflix.com/2012/11/hystrix.html
Simian Army/Chaos Monkey
测试Microservices的稳定性一直是个世界级难题,Netflix拥有上百个services,无数种挂掉的combination,作为一个程序猿,我怎么知道在每一种scenario下Netflix是否还能正常运行?你需要另一个猴子帮你:Introducing Simian Army and Chaos Monkey。
Simian Army直译就是类人猿军队,是一个测试套装。其中最有名的就是Chaos Monkey,直译就是制造混乱的猴子。
这个猴子用来干什么呢?它在所有service的dependency graph里,每次随机挑几个service,把它们弄挂(当然testing是在test stage进行的,这时候spinnaker就派上用场了),看看Netflix as a whole的输出结果是否还是expected的(expected behavior严重依赖于Hystrix)。
笔者工作中也进行过很多次gameday,一起测试org下的几十个services,但每一次都是固定的测试某些个系统挂掉的scenario。当笔者第一次看presentation听到这个tool的时候可想而知是相当被震撼到的,也深深的成为了Netflix的脑残粉。
Link: http://techblog.netflix.com/2012/07/chaos-monkey-released-into-wild.html
小结
甩了一堆纯干货,想必大家都有点审美疲劳。我们歇一下,这篇就讲到这里。
如果你问本文涵盖了所有Netflix OSS的精华么?答案是否定的。笔者所希望的是,以后当你考虑用一个架构,或者在实践中发现了一个painpoint而且觉得是一个distributed system的通用问题的时候,不妨搜一搜Netflix OSS,说不定早就被Netflix的架构师解决了。
Comments
Post a Comment
https://gengwg.blogspot.com/