What are File Descriptors in Linux?
A file descriptor is a positive integer that acts as a unique identifier (or handle) for “files” and other I/O resources, such as pipes, sockets, blocks, devices, or terminal I/O.
All the file descriptor records are kept in a file descriptor table in the kernel. When a file is opened, a new file descriptor (or integer value) is given to that file in the file descriptor table.
For example, if you open a “example_file1.txt” file (which is nothing but a process), it will be allocated with the available file descriptor (for example, 101), and a new entry will be created in the file descriptor table.
And when you open another file like “example_file2.txt“, it will be allocated to another available file descriptor like 102, and another entry will be created in the file descriptor table.
| File Descriptor | Process |
|---|---|
| 101 | example_file1.txt |
| 102 | example_file2.txt |
The file descriptor for the referenced file will be available for use by another process once you close the file.
Short Recap: A file descriptor is a unique, non-negative number that is given to each process or other I/O resource (when they make a successful request) in the kernel’s file descriptor table. Once the file is closed, the file descriptor can be given to another process.
So, when you open hundreds of files or other I/O resources in your Linux system, there will be 100 entries in the file descriptor table, and each entry will reference a unique file descriptor (or integer value like 100, 102, 103…) to identify the file.
What is the File Descriptor Table in Linux?
When a process or I/O device makes a successful request, the kernel returns a file descriptor to that process and keeps the list of current and all running process file descriptors in the file descriptor table, which is somewhere in the kernel.
Now, your process might depend on other system resources like input and output; as this event is also a process, it also has a file descriptor, which will be attached to your process in the file descriptor table.
Each file descriptor in the file descriptor table points to an entry in the kernel’s global file table. The file table entry maintains the record of file (or other I/O resource) modes like (r)ead, (w)rite, and (e)xecute.
Also Read: What is inode in Linux?
Also, the file table entry points to a third table known as the inode table that points to actual file information like size, modification date, pointer, etc.
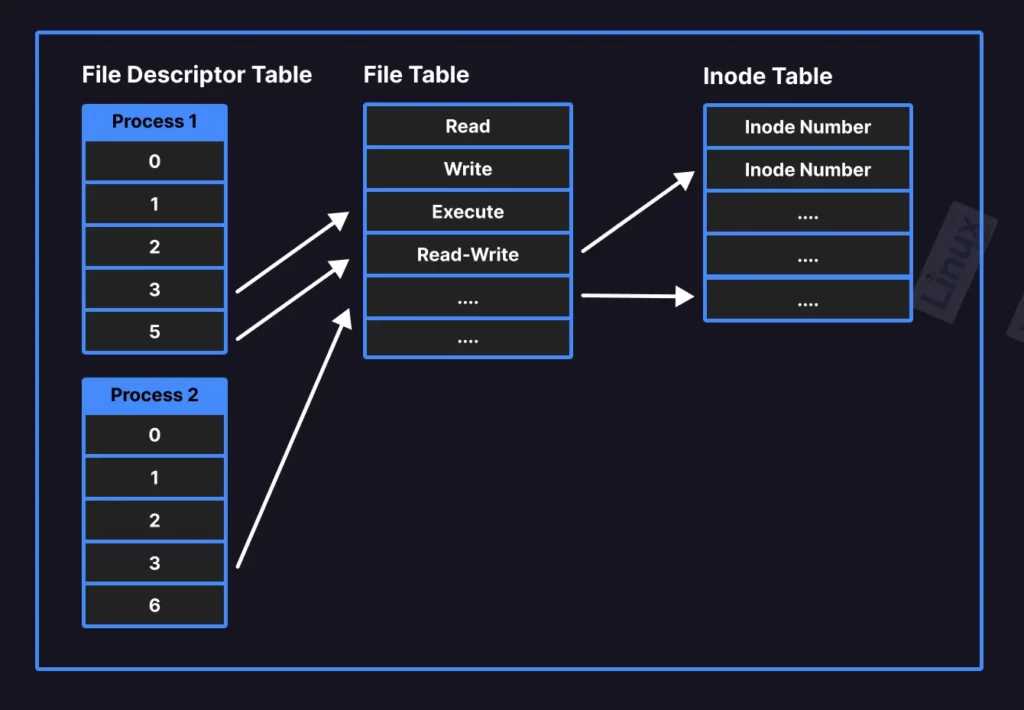
Predefined File Descriptors
By default, three types of standard POSIX file descriptors exist in the file descriptor table, and you might already be familiar with them as data streams in Linux:
| File Descriptor | Name | Abbreviation |
|---|---|---|
| 0 | Standard Input | stdin |
| 1 | Standard Output | stdout |
| 2 | Standard Error | stderr |
Apart from them, every other process has its own set of file descriptors, but few of them (except for some daemons) also utilize the above mentioned file descriptors to handle input, output, and errors for the process.
To make sure that the process is using the above file descriptor, just look for the above file descriptor (in integer format) under “/proc/PID/fd/“, where PID stands for “process identifier.”
For example, I’ve started the GEDIT editor on my system, which uses all of the file descriptors mentioned above, as shown.
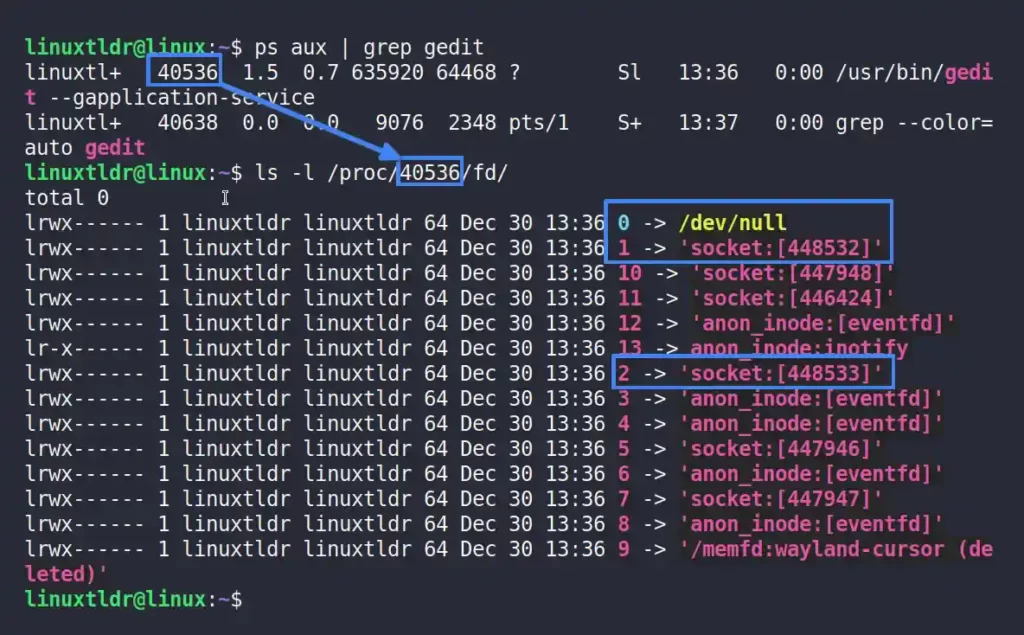
List all of a Running Process’s File Descriptors
As you just learned, each running process in Linux has its own set of file descriptors, but it also uses others to identify the specific file when communicating with kernel space via system calls or library calls.
Find the Process ID (or PID)
First, find out your process identifier (or PID) using the ps command before viewing the file descriptors under it.
$ ps aux | grep geditReplace “gedit” with your running process name, or you can place “$$” to pass the current bash session.
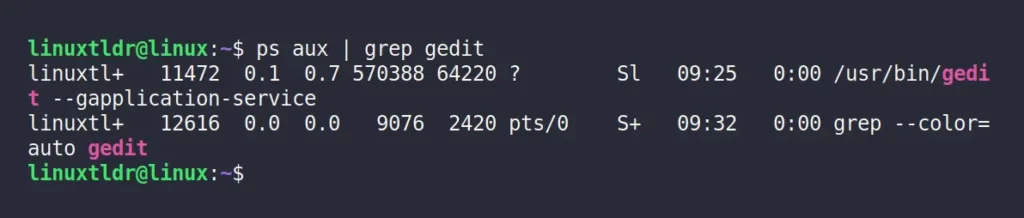
Now, you have two ways to list the file descriptors under a specific process, followed by:
Using the ls command
List all of the file descriptors and the files they refer to under a certain PID by listing the content of the “/proc/PID/fd/” path, where PID is the process ID using the ls command.
Also Read: Everything About /proc File System in Linux
$ ls -la /proc/11472/fd/Output:
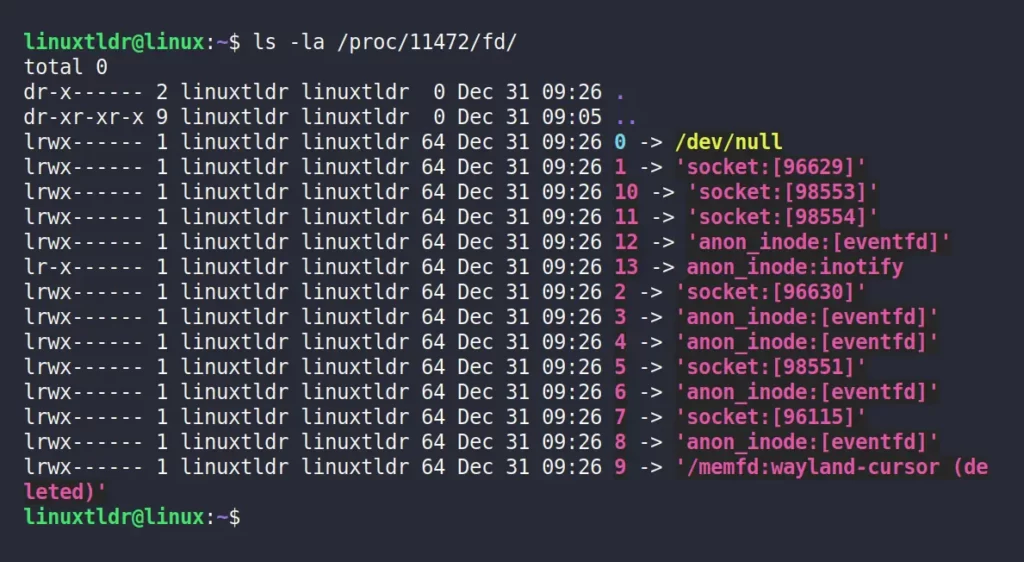
Using the lsof command
The lsof command is used to list the information of running processes in the system and can also be used to list the file descriptor under a specific PID.
For that, use the “-d” flag to specify a range of file descriptors, with the “-p” option specifying the PID. To combine this selection, use the “-a” flag.
$ lsof -a -d 0-2147483647 -p 11472Output:
What is the Purpose of File Descriptors in the First Place?
The file descriptor, along with the file table, keep track of each running process’s permissions in your system and maintain data integrity.
A running process can inherit the functionality of another process by inheriting its file descriptor, as you just learned in this article.
What Happens If You Run Out of File Descriptors?
This is crucial because a file descriptor is an integer value that the kernel returns to the process (or other I/O resource) after a successful attempt to open a file.
There is a limit to the number of file descriptors (or integer values) that can be given to a process. When that limit is reached, data can be lost.
In Linux, generally, there are two types of file descriptors: process-level file descriptors and system-level file descriptors.
Process-Level File Descriptor Limits
Check the current process-level file descriptor limit using the ulimit command.
$ ulimit -nOutput:

Reset the limit by adding a custom positive number after the command.
$ ulimit -n 3276800Note that non-root users are also able to use the above command to change the process-level limits (<Kernel 2.4.x), but you need to add the following lines in “/etc/security/limits.conf” to assign the user modification permission:
soft nofile 2048
hard nofile 8192System-Level File Descriptor Limits
Check the limit of the system-level descriptor using the cat command.
$ cat /proc/sys/fs/file-maxOutput:

Modify the file with the new value by using the “>” redirection symbol.
$ echo 90000 > /proc/sys/fs/file-maxAfter modifying the above file, modify the value in the “nr_open” file.
$ echo "50000" > /proc/sys/fs/nr_open
Comments
Post a Comment
https://gengwg.blogspot.com/